Secuencias#
Secuencias de datos
Listas
Tuplas
Rangos
Operaciones comunes de las secuencias
Operaciones para secuencias mutables
Operadores de comparación con secuencias
Casos de uso de listas y tuplas
Cadenas de caracteres
Secuencias de datos#
En muchas aplicaciones resulta conveniente ser capaz de almacenar en memoria, para luego manipular a conveniencia y de forma consistente, un determinado conjunto de datos.
Hasta el momento, hemos introducido tipos de datos escalares, int, float, complex y bool, datos que conceptualmente contienen un único valor. Y de hecho, ya hemos introducido un contenedor de datos, las cadenas de caracteres str.
Supongamos, por un momento, que se desea retener un conjunto de 5 enteros en memoria, para luego manipularlos, posiblemente de diversas formas: sumándolos, o hallando el máximo de los mismos, o graficándolos, etc.
Con lo visto hasta ahora el recurso lógico es definir 5 variables enteras y tratarlas individualmente:
a0 = 10
a1 = 5
a2 = 1
a3 = 130
a4 = -2
suma = a0 + a1 + a2 + a3 + a4
¿Qué solución adoptaríamos si ahora se necesitaran 100 variables? Habría que crear otras tantas variables, con nombres diferentes y extender el código previo manteniendo la idea básica. ¡Algo impracticable!
Para tratar estas situaciones, Python dispone de tipos nativos que actúan como contenedores (containers) de datos, que cubren esa necesidad.
Contenedores en Python#
Todos los lenguajes de programación ofrecen la posibilidad de trabajar con colecciones de datos de una forma consistente. Por ejemplo, en C/C++ se tiene el concepto de vector (array).
Python ofrece un conjunto de opciones muy efectivas y flexibles para resolver este tipo de problemas. Permiten representar tipos de datos contenedores de otros datos de forma nativa.
Los tipos nativos contenedor más relevantes son:
Nombre |
Tipo |
Ejemplo |
Descripción |
|---|---|---|---|
Lista |
|
|
Secuencia heterogénea de datos mutable |
Tupla |
|
|
Secuencia heterogénea de datos inmutable |
Rango |
|
|
Secuencia de enteros inmutable |
Cadena de caracteres |
|
|
Secuencia de caracteres inmutable |
Diccionario |
|
|
Tabla asociativa de valores únicos (clave, valor) |
Conjunto |
|
|
Colección sin orden de valores únicos |
El uso de corchetes, [], paréntesis, () o llaves, {}, es lo que distingue entre sí la naturaleza de algunos de los contenedores anteriores.
Secuencias en Python#
Las secuencias son contenedores donde los elementos se almacenan siguiendo un orden. Listas, tuplas y rangos son las secuencias básicas que define Python. Además, un tipo de dato que ya conocemos, la cadena de caracteres, es también una secuencia ordenada de caracteres alfanuméricos.
Entre las secuencias destacan las listas, tipo list, a las que prestaremos la atención en primer lugar.
Listas#
En la siguiente celda, se define una variable lista llamada lista_enteros asignándola una colección de valores caracterizada por:
una secuencia de literales enteros
separados por comas
delimitados por corchetes
lista_enteros = [10, 5, 1, 130, -2]
print(f'El tipo de {lista_enteros} es {type(lista_enteros)}.')
El tipo de [10, 5, 1, 130, -2] es <class 'list'>.
El concepto de lista impone necesariamente una relación de orden, una secuencia.
Observe además que la variable de tipo list puede ser enviada como argumento real a la función print(), que la interpreta correctamente y la saca por la consola de la forma esperada.
La variable lista_enteros representa a la colección completa. Pero este recurso del lenguaje no sería tan útil si no permitiera el acceso individual a cada uno de los enteros contenidos en la colección.
Indexación#
La indexación permite acceder a un miembro individual de la lista.
Véase el ejemplo siguiente (se debe haber ejecutado antes la celda previa):
x = lista_enteros[0]
y = lista_enteros[1]
z = lista_enteros[4]
print(x, y, z)
10 5 -2
En la celda anterior, se almacenan en variables ciertos valores de la secuencia.
Para acceder a un miembro individual de la lista:
se utiliza un índice, siempre de tipo entero, que indica la posición del dato miembro dentro de la colección
el índice se pone entre corchetes
[], que actúan como un operador de indexaciónal primer elemento de la secuencia le corresponde siempre el valor
0
Dado que una lista implementa una secuencia, el elemento de índice i aparece siempre antes que el elemento i+1 si se está recorriendo la lista desde la izquierda.
A diferencia de otros lenguajes, Python permite que el índice pueda especificarse también desde la derecha, utilizando enteros negativos: el índice -1 hace referencia al último elemento de la lista (o al primero desde la derecha).
Vea el siguiente esquema:
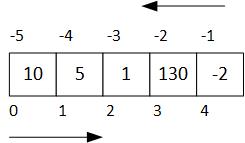
print(lista_enteros[-1], lista_enteros[-2])
-2 130
Si se intenta acceder a un elemento no existente dentro de la secuencia, se produce un error en tiempo de ejecución:
lista_enteros[5]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[4], line 1
----> 1 lista_enteros[5]
IndexError: list index out of range
Es muy importante que el alumno se habitúe a identificar el tipo de error que se lanza al producirse la excepción y, con ello, corregir el fallo. En este caso:
la descripción del error:
IndexError: list index out of range, yla línea donde se produce el error:
----> 1 lista_enteros[5],
nos dan toda la información necesaria acerca de la causa y situación del error.
Mutabilidad#
Una lista es, además, una secuencia mutable. Esto quiere decir que se pueden:
modificar los elementos de la lista
borrar determinados elementos
añadir elementos nuevos
etc.
En la celda siguiente, podemos observar mediante la función id() que la identidad del objeto no ha cambiado, pero su contenido sí.
lista = [0, 1, 2, 3]
print(f'Lista {lista} antes de modificarla y su identidad: {id(lista)}.')
lista[0] = lista[1] + lista[2] # Modificamos el elemento [0]
print(f'Lista {lista} después de modificarla y su identidad: {id(lista)}.')
Lista [0, 1, 2, 3] antes de modificarla y su identidad: 2481789664320.
Lista [3, 1, 2, 3] después de modificarla y su identidad: 2481789664320.
Lista vacía#
En muchas ocasiones, los algoritmos construyen iteradamente una lista a partir de una lista vacía, que se construye con los corchetes vacíos.
lista = []
Menos habitual, también es posible partir de una lista vacía con el constructor de listas sin argumentos list():
lista = list()
Tuplas#
Las tuplas, tipo tuple, representan, al igual que las listas, una secuencia de valores en Python.
A diferencia de las listas, las tuplas son inmutables: una vez creadas no pueden modificarse.
Una tupla se crea asignando un conjunto de valores a una variable. Los valores están separados entre sí por una coma y opcionalmente pueden estar rodeados de paréntesis.
Por ejemplo:
datos_asig = 'Fundamentos de Programación', 40, 1, 2
print(datos_asig)
otra_tupla = (1, 2, 3) # Uso de paréntesis opcional
print(otra_tupla)
('Fundamentos de Programación', 40, 1, 2)
(1, 2, 3)
Nótese que, aunque los paréntesis son opcionales, pueden aportar una mejor legibilidad.
Tuplas con un solo elemento#
Se pueden crear tuplas de un solo elemento. Cómo podría existir ambigüedad, se tiene que poner una coma al final.
tupla_con_un_elemento = (10,)
otra_tupla_con_un_elemento = 'Hola',
una_tupla = 'Hola',
una_cadena = 'Hola'
print(f'''{una_tupla} es una tupla, {type(una_tupla)},
mientras que {una_cadena} es una cadena {type(una_cadena)}''')
una_tupla = (3,)
otra_tupla = 5,
un_entero = (3)
print(f'{una_tupla} o {otra_tupla} son tuplas mientras que {un_entero} es un entero')
('Hola',) es una tupla, <class 'tuple'>,
mientras que Hola es una cadena <class 'str'>
(3,) o (5,) son tuplas mientras que 3 es un entero
Tuplas vacías#
También pueden existir tuplas vacías, usando paréntesis sin contenido o el constructor de tuplas sin argumentos tuple():
tupla_vacia = ()
otra_tupla_vacia = tuple()
Indexación#
Al igual que con las listas, se puede acceder a los elementos de las tuplas con el operador de indexación [].
x = 3, 7, 9, 10
print(x[0] + x[-1])
13
Inmutabilidad#
Sin embargo, dado su carácter inmutable, lo que no se puede es modificar los valores ni el tamaño de la tupla una vez creada.
x[1] = 10 # La ejecución de esta línea provoca un error al ser las tuplas inmutables
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[12], line 1
----> 1 x[1] = 10
TypeError: 'tuple' object does not support item assignment
Desempaquetado de una tupla#
Los elementos de una tupla se pueden asignar a tantas variables como elementos haya en la misma en un proceso llamado desempaquetado (unpacking).
datos_ciudad = ('Valladolid', 'Castilla y León', 'España')
ciudad, comunidad, pais = datos_ciudad
print(f'Ciudad: {ciudad}\nComunidad: {comunidad}\nPaís: {pais}')
Ciudad: Valladolid
Comunidad: Castilla y León
País: España
En el ejemplo, se han creado nuevas variables con nombre, ciudad, comunidad y pais, que contienen las cadenas de caracteres incluidas en las posiciones 0, 1, 2 de la tupla datos_ciudad.
Nótese que el desempaquetado es el mecanismo del lenguaje que se pone en juego cuando se hacen asignaciones múltiples en Python:
a, b = 1, 2
Lo que ocurre en esa sentencia es lo que sigue:
Previo a la operación de asignación, se crea un objeto tupla empaquetando los elementos
1y2(recuérdese que los paréntesis son opcionales)Se procede a la asignación. Como aparece a la izquierda del operador
=más de una variable, se procede al desempaquetado o asignación a las variablesayb.
Veremos la utilidad de este esquema a lo largo del curso. En particular, es muy útil para el intercambio de los valores de dos variables, una operación que se requiere con alguna frecuencia en programación:
x = 2
y = 3
x, y = y, x
print('x = ', x, '\ny = ', y)
x = 3
y = 2
En un lenguaje como C/C++, el intercambio de valores necesita de una variable intermedia. El equivalente en Python sería el siguiente código:
x = 2
y = 3
aux = x
x = y
y = aux
print('x = ', x, '\ny = ', y)
x = 3
y = 2
El número de variables a asignar en el desempaquetado debe coincidir con el tamaño de la tupla. En caso contrario, se lanzará una excepción.
x, y = 1, 2, 3 # Demasiados valores a desempaquetar
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[17], line 1
----> 1 x, y = 1, 2, 3
ValueError: too many values to unpack (expected 2)
x, y = 1, # Pocos valores a desempaquetar
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[18], line 1
----> 1 x, y = 1,
ValueError: not enough values to unpack (expected 2, got 1)
Rangos#
Un rango es una secuencia inmutable de enteros que, como veremos, se usa habitualmente con bucles. Los bucles permiten la ejecución de un grupo de sentencias un número determinado de veces.
La construcción de un rango de enteros admite varias sintaxis. Los parámetros start, stop y step que utilizan los rangos son siempre enteros:
range(stop)
La secuencia de enteros representada es el intervalo abierto \([0, stop)\), es decir, la secuencia
0, 1, 2, ..., stop-1. Sistop <= 0la secuencia no tendrá elementos.range(start, stop)
La secuencia de enteros representada es el intervalo abierto \([start, stop)\), es decir, la secuencia
start, start+1, start+2, ..., stop-1. Sistop <= startla secuencia no tendrá elementos.range(start, stop, step)
La secuencia de enteros representada es
start, start+1*step, start+2*step, ..., start+i*step.Si
stepes un entero positivo, la secuencia finalizará para aquel valori >= 0para el questart+(i+1)*step >= stopSi
stepes un entero negativo, la secuencia finalizará para aquel valori >= 0para el questart+(i+1)*step <= stop
Nótese como el valor correspondiente a stop nunca pertenecerá al rango.
A diferencia de las secuencias list o tuple, un objeto de tipo range no almacena los valores de la secuencia en memoria, con el consiguiente ahorro de recursos. Solo necesita guardar en los atributos correspondientes los valores para start, stop y step: calcula dinámicamente los valores intermedios a medida que se van necesitando, empezando por el primero y terminando por el último.
r = range(1, 10, 2)
print(r.start, r.stop, r.step)
1 10 2
Listas y tuplas a partir de rangos#
Como hemos visto para listas y tuplas vacías, tanto las listas como las tuplas tienen constructores, list() y tuple(). Estos constructores admiten un rango como parámetro para ser creadas. Veámoslos en acción.
# Enteros del 0 al 9
lista = list(range(10))
print("Lista construida con range(10):\n {}".format(lista))
# Enteros del 5 al 14
tupla = tuple(range(5, 15))
print("Tupla construida con range(5, 15):\n {}".format(tupla))
# Pares del 4 al 20
lista = list(range(4, 21, 2))
print("Lista construida con range(4, 21, 2):\n {}".format(lista))
# Secuencia del 3 al -12 en pasos de -3
tupla = tuple(range(3, -13, -3))
print("Tupla construida con range(3, -13, -3):\n {}".format(tupla))
Lista construida con range(10):
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Tupla construida con range(5, 15):
(5, 6, 7, 8, 9, 10, 11, 12, 13, 14)
Lista construida con range(4, 21, 2):
[4, 6, 8, 10, 12, 14, 16, 18, 20]
Tupla construida con range(3, -13, -3):
(3, 0, -3, -6, -9, -12)
Operaciones comunes de las secuencias#
El operador de pertenencia in#
El operador de pertenencia in comprueba si un determinado valor forma parte de una secuencia. El operador in
devuelve un valor booleano, True o False, por lo que el operador conjunto not in devolverá justo el resultado contrario.
Operador |
Descripción |
|---|---|
|
Devuelve |
|
Devuelve |
lista = [1, 3, 5, 7, 2, 4, 6]
if 2 in lista:
print('El valor 2 está en la lista', lista)
rango = range(10)
if 10 not in rango:
print('El valor 10 no está en', rango)
El valor 2 está en la lista [1, 3, 5, 7, 2, 4, 6]
El valor 10 no está en range(0, 10)
En la siguiente celda retomamos el ejemplo del tema anterior referente a la determinación del número de días de un mes.
Véase la elegante combinación de tuplas y el operador de pertenencia in para resolver el problema.
# Estructura condicional anidada (if ... elif ...else) (con tuplas y operador in)
mes_31 = (1, 3, 5, 7, 8, 10, 11)
mes_30 = (4, 6, 9, 11)
mes = int(input("Introduzca el mes del año: "))
if mes in mes_31:
print("El mes tiene 31 días.")
elif mes in mes_30:
print("El mes tiene 30 días.")
elif mes == 2:
print("El mes tiene 28 o 29 días.")
else:
print("Mes no válido.")
Concatenación#
El operador + actúa de forma sobrecargada para formar secuencias lista o tupla concatenadas.
lista = [1, 2, 3] + [6, 7, 8]
print(lista)
[1, 2, 3, 6, 7, 8]
El operador * concatena consigo mismo una secuencia un determinado número n de veces.
Resulta un recurso conveniente para inicializar una secuencia de tamaño conocido n con un valor o un patrón dado.
num = 10
tupla = (0,)*num
print(f"Una tupla de {num} elementos inicializada a 0:\n {tupla}")
Una tupla de 10 elementos inicializada a 0:
(0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
Para concatenar listas y tuplas se puede usar el operador sobrecargado +=. Debe notarse que en el caso de tuplas no se mantiene la identidad de la tupla original, algo lógico dado su inmutabilidad.
tupla = 1, 2
identidad = id(tupla)
tupla += 3, 4
print(f'''La nueva tupla {tupla} tiene una identidad {id(tupla)},
que es diferente de la original, {identidad}''')
La nueva tupla (1, 2, 3, 4) tiene una identidad 2481795252288,
que es diferente de la original, 2481789678144
Por razones obvias, los operadores +, += y * no están permitidos en los tipos range, dado que su aplicación generaría con caracter general una secuencia que no correspondería a un rango.
Obteniendo información de la secuencia#
La longitud de la secuencia len()#
Permite obtener el número de elementos.
lista = [1, 2, 3, 4, 5]
rango = range(1, 10, 2)
print(f"El número de elementos de {lista} es {len(lista)}")
print(f"El número de elementos de {rango} es {len(rango)}")
El número de elementos de [1, 2, 3, 4, 5] es 5
El número de elementos de range(1, 10, 2) es 5
Los valores extremos: min() y max()#
Permiten obtener el valor mínimo o máximo de la secuencia. En el caso de cadenas, se sigue el orden lexicográfico.
lista = [1, 2, 3, 4, 5]
rango = range(10)
tupla = ('Hola', 'Adiós', 'Buenos días')
print(f"El valor mínimo de {lista} es {min(lista)}")
print(f"El valor máximo de {rango} es {max(rango)}")
print(f"El valor máximo de {tupla} es {max(tupla)}")
El valor mínimo de [1, 2, 3, 4, 5] es 1
El valor máximo de range(0, 10) es 9
El valor máximo de ('Hola', 'Adiós', 'Buenos días') es Hola
Estas y otras funciones similares no tiene sentido utilizarlas en secuencias heterogéneas. Tanto min() como max() utilizan el operador < para comparar entre sí los elementos. Si la secuencia tiene tipos incompatibles con este operador,
se lanzará una excepción. Véase un ejemplo:
min([1, 2, 'hola'])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[28], line 1
----> 1 min([1, 2, 'hola'])
TypeError: '<' not supported between instances of 'str' and 'int'
Posición de un elemento y número de ocurrencias#
Mediante la función miembro .index(x) podemos obtener la posición de la primera ocurrencia del valor x en la secuencia. Si no se encuentra el valor x se genera una excepción.
lista = [2, 4, 6, 8, 10]
rango = range(12, 0, -2)
x = 6
print(f'El valor {x} ocupa la posición {lista.index(x)} en la lista {lista}')
print(f'El valor {x} ocupa la posición {rango.index(x)} en el rango {rango}')
x = 14
print("Si el valor no se encuentra se genera una excepción ValueError:")
rango.index(x)
El valor 6 ocupa la posición 2 en la lista [2, 4, 6, 8, 10]
El valor 6 ocupa la posición 3 en el rango range(12, 0, -2)
Si el valor no se encuentra se genera una excepción ValueError:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[29], line 8
6 x = 14
7 print("Si el valor no se encuentra se genera una excepción ValueError:")
----> 8 rango.index(x)
ValueError: 14 is not in range
Las secuencias también disponen del método .count(x) para determinar cuantas veces aparece el valor x en la secuencia.
tupla = 1, 1, 2, 3, 1
x = 1
print(f'El valor {x} aparece {tupla.count(x)} veces en la tupla {tupla}')
El valor 1 aparece 3 veces en la tupla (1, 1, 2, 3, 1)
Cortes (slices)#
Los cortes o rebanadas son subsecuencias extraídas de otra secuencia.
Por ejemplo, dada la secuencia
[1, 3, 5, 7, 2, 4, 6], la secuencia [3, 5, 7, 2] es un corte de la primera obtenido entre los índices 1 y 5, este último sin incluir.
El operador de corte [i:j] selecciona de la secuencia original aquella fomada por los valores situados en las posiciones i, i+1, ..., j-1.
lista = [1, 3, 5, 7, 2, 4, 6]
sublista = lista[1:5]
print(sublista)
[3, 5, 7, 2]
Aunque de gran uso en diferentes ámbitos de la programación en Python, en este curso introductorio utilizaremos con poca frecuencia este potente y versátil operador. Se comenta aquí con el único propósito de que el alumno reconozca este operador cuando maneje la bibliografía.
Ordenación#
Es posible obtener una lista ordenada, tipo list, a partir de una secuencia con la función nativa sorted(). Los elementos de la secuencia deben tener un tipo para los que esté definido el concepto de orden, es decir, el operador <.
lista = sorted((1, 3, 5, 7, 9, 2, 4, 6, 8))
print(lista)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Para ordenar los elementos de mayor a menor, sorted() tiene un argumento booleano opcional, reverse, que permite conseguir este propósito.
lista = sorted(range(10), reverse=True)
print(lista)
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
Operaciones para secuencias mutables#
El contenedor list es la principal secuencia nativa mutable de Python y, sin duda, el contenedor más utilizado. La regla básica de uso de una operación es que si supone una modificación de la secuencia, entonces no es aplicable a una secuencia inmutable, como una tupla o un rango.
El operador de asignación =#
Ya hemos visto más arriba que un elemento de una secuencia puede modificarse individualmente.
lista = [1, 2, 3, 4, 5]
lista[0] = 100
print(lista)
[100, 2, 3, 4, 5]
Borrando elementos#
El operador del#
El operador del tiene el propósito de desligar los identificadores con el objeto en memoria. Puede aplicarse a variables simples (tipo int, float, etc.) y también a secuencias mutables.
Cualquier utilización posterior de la variable previa a una nueva asociación a otro objeto generará una excepción NameError.
x = 3
del(x)
print(x)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[35], line 3
1 x = 3
2 del(x)
----> 3 print(x)
NameError: name 'x' is not defined
El operador del también puede ser usado para borrar elementos concretos de la lista de la forma que se muestra a continuación:
lista = ["lista", "palabras", "sueltas", "representadas", "por", "cadenas"]
indice = 1
print('De la lista:\n', lista)
del lista[indice]
print(f'se borra el elemento {indice}, obteniendo la nueva lista\n {lista}')
# Ahora se elimina la lista de memoria
del lista
print('Si intentamos acceder a la lista tras eliminarla se genera una excepción NameError.');
lista
De la lista:
['lista', 'palabras', 'sueltas', 'representadas', 'por', 'cadenas']
se borra el elemento 1, obteniendo la nueva lista
['lista', 'sueltas', 'representadas', 'por', 'cadenas']
Si intentamos acceder a la lista tras eliminarla se genera una excepción NameError.
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[36], line 9
7 del lista
8 print('Si intentamos acceder a la lista tras eliminarla se genera una excepción NameError.');
----> 9 lista
NameError: name 'lista' is not defined
También es posible eliminar con del un corte de la lista.
lista = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
del lista[1:-1] # Elimina desde el índice 1 hasta el -1 menos 1, es decir, hasta el -2
print(lista)
[0, 9]
Los métodos .pop(), .remove() y .clear()#
.pop()y.pop(i)reducen el tamaño de la secuencia en uno:.pop()elimina el último elemento: equivale a pasar el argumento-1.pop(i)elimina el elemento de índicei
Este método devuelve el elemento eliminado. Si se usa un índice que no es válido se genera una excepción
IndexError..remove(x)permite borrar la primera aparición del elementox.Debe usarse con prudencia: si se intenta eliminar un valor que no existe en la lista, se genera una excepción
ValueError..clear()borra todo el contenido de la lista, dejando la lista vacía,[].
lista = [0, 1, 2, 3, 4, 5, 5, 6, 7, 8, 9]
valor = lista.pop()
print(f'Con pop() hemos eliminado el último elemento, de valor {valor}.')
valor = lista.pop(2)
print(f'Usando pop(2) hemos eliminado el tercer elemento, de valor {valor}.')
lista.remove(5)
print('Con remove(5) eliminamos el primer elemento coincidente con 5. La lista es ahora\n', lista)
lista.clear()
print('Con clear() la lista se vacía:\n', lista)
Con pop() hemos eliminado el último elemento, de valor 9.
Usando pop(2) hemos eliminado el tercer elemento, de valor 2.
Con remove(5) eliminamos el primer elemento coincidente con 5. La lista es ahora
[0, 1, 3, 4, 5, 6, 7, 8]
Con clear() la lista se vacía:
[]
lista = [1, 2, 3]
lista.pop(3) # Excepción index out of range
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[39], line 2
1 lista = [1, 2, 3]
----> 2 lista.pop(3)
IndexError: pop index out of range
lista = [1, 2, 3]
lista.remove(4) # Excepción ValueError
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[40], line 2
1 lista = [1, 2, 3]
----> 2 lista.remove(4)
ValueError: list.remove(x): x not in list
Añadiendo elementos#
Concatenación#
Para concatenar la secuencia original con otra se puede usar el operador sobrecargado += o el método .extend(). Como ya hemos comentado, en el caso de listas, se mantiene la identidad de la lista original.
# Concatenando listas
a = [1, 2, 3]
print(f'La identidad de la lista {a} es: {id(a)}')
b = [4, 5, 6]
c = [7, 8, 9]
a += b
print(f'Tras concatenarla usando el operador += con la lista {b} obtenemos:\n {a}')
a.extend(c)
print(f'Tras concatenarla usando el método extend() con la lista {c} obtenemos:\n {a}')
print(f'La identidad de la lista {a} es la original: {id(a)}')
La identidad de la lista [1, 2, 3] es: 2481795545152
Tras concatenarla usando el operador += con la lista [4, 5, 6] obtenemos:
[1, 2, 3, 4, 5, 6]
Tras concatenarla usando el método extend() con la lista [7, 8, 9] obtenemos:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
La identidad de la lista [1, 2, 3, 4, 5, 6, 7, 8, 9] es la original: 2481795545152
Si lo que deseamos es actualizar la lista con su contenido repetido n veces, puede utilizarse el operador *=
lista = [1, 2, 3]
lista *= 3
print(lista)
[1, 2, 3, 1, 2, 3, 1, 2, 3]
Añadir al final de la secuencia un elemento#
El método .append() añade un único elemento al final de la lista. Dicho elemento podría ser cualquier otro objeto de Python, incluso otra lista.
a = [] # ¡Lista vacía!
a.append(1)
a.append(2)
a.append(3)
print('La lista, inicialmente vacía, tras añadir sucesivamente los elementos 1, 2 y 3 es:\n', a)
a.append([1, 2, 3])
print('Ahora hemos añadido un cuarto elemento, ¡que es una lista!:\n', a)
La lista, inicialmente vacía, tras añadir sucesivamente los elementos 1, 2 y 3 es:
[1, 2, 3]
Ahora hemos añadido un cuarto elemento, ¡que es una lista!:
[1, 2, 3, [1, 2, 3]]
Insertando elementos en una posición arbitraria#
Se hace uso del método .insert() que posee dos parámetros, la posición (un entero) y el elemento único a insertar (si el elemento es a su vez una lista, se inserta como una sublista).
Este método tiene la particularidad de que si la posición de inserción sobrepasa los límites de la secuencia, entonces se inserta el elemento bien al principio, si se sobrepasa por defecto, bien al final, si se sobrepasa por exceso.
a = [1, 2, 3, 4]
a.insert(1,25)
a.insert(10,100)
a.insert(-10,-100)
print(a)
[-100, 1, 25, 2, 3, 4, 100]
Invirtiendo la secuencia#
El método .reverse() invierte el orden de la secuencia.
lista = [1, 2, 3, 4, 5]
lista.reverse()
print(lista)
[5, 4, 3, 2, 1]
Ordenando la secuencia#
Para aquellas secuencias mutables formadas por elementos para cuyos tipos esté definido el concepto de orden, es decir, el operador <, es posible ordenar los elementos de menor a mayor con el método .sort(). A diferencia de sorted() es la propia secuencia la que se ordena: ¡no se crea una diferente! De ahí que solo sea aplicable a secuencias mutables.
lista = [1, 3, 5, 7, 9, 2, 4, 6, 8]
lista.sort()
print(lista)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Para ordenar los elementos de mayor a menor bastaría aplicar el método .reverse() tras .sort(). Sin embargo, sería ineficiente para listas de gran número de elementos. Al igual que sorted(), el método .sort() tiene el argumento opcional reverse que permite conseguir este propósito.
lista = [1, 3, 5, 7, 9, 2, 4, 6, 8]
lista.sort(reverse=True)
print(lista)
[9, 8, 7, 6, 5, 4, 3, 2, 1]
Copia superficial y copia profunda#
Ya sabemos que el uso del operador = para copiar una lista, en realidad lo que logra es crear una nueva referencia al mismo objeto de memoria, que es además mutable. Muchas veces es precisamente esto lo que se quiere lograr: dar un nuevo nombre, un alias al objeto subyacente: el contenido de la lista almacenado en memoria.
Pero en otras ocasiones queremos obtener otra lista que tenga los mismos elementos, pero que haga referencia a objetos distintos en memoria, aunque sus valores sean los mismos. En este caso, lo apropiado es hacer realmente una copia de los datos.
Esto se puede realizar, para el caso de listas no anidadas, utilizando cortes o con la función list():
vector1 = [1.1, 2.0, 4.5]
vector2 = vector1[:]
vector3 = list(vector1)
vector2[0] = 100
vector3[1] = 1000
print(vector1, vector2, vector3)
[1.1, 2.0, 4.5] [100, 2.0, 4.5] [1.1, 1000, 4.5]
Otra forma de realizar la copia superficial anterior es usando el método copy() de las listas.
a = [1, 2, 3, "a"]
b = a
print("Tras b = a, ¿'a' es igual a 'b'? ", a == b)
print("De hecho 'b' es un alias de 'a'. ¿La memoria es la misma? ", a is b)
c = b.copy()
print("Tras c = b.copy(), ¿'b' sigue siendo igual a 'c'? ", b == c)
print("¿Constituyen el mismo objeto en memoria? ", b is c)
Tras b = a, ¿'a' es igual a 'b'? True
De hecho 'b' es un alias de 'a'. ¿La memoria es la misma? True
Tras c = b.copy(), ¿'b' sigue siendo igual a 'c'? True
¿Constituyen el mismo objeto en memoria? False
Copia superficial (shallow copy)#
Para secuencias más complicadas como, por ejemplo, la lista del ejemplo siguiente, los formatos de copia vistos más arriba tampoco brindan el resultado satisfactorio que se busca de obtener dos listas completamente separadas.
a = [5, 2, [3, 4]]
b = a[:]
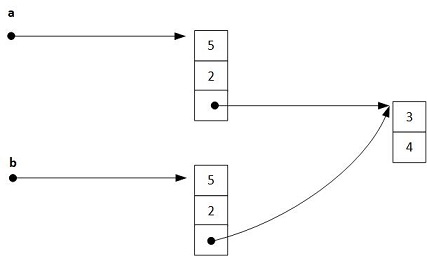
Se puede observar en el diagrama que la sublista [3, 4] que está incluida en a, es accedida a su vez mediante una referencia que apunta a las localizaciones de memoria que realmente la almacenan. Cuando ahora se realiza la copia bit a bit de a hacia b utilizando cortes, se copian, no los datos de la sublista, sino los bits (apuntadores) que hacen referencia a la misma. La copia que se logra de esta forma es una copia superficial (shallow copy).
Si ahora se cambia el valor del primer elemento de la lista a:
a[0] = 10
solamente se modifica la copia que pertenece en exclusiva a dicha variable.
Pero si se intenta modificar un elemento de la sublista que aparece como tercer elemento de a, se modificará la lista compartida común entre a y b.
a[2][0] = 20
a = [5, 2, [3, 4]]
b = a[:]
a[0] = 10
a[2][0] = 20
print('a: ', a)
print('b: ', b)
a: [10, 2, [20, 4]]
b: [5, 2, [20, 4]]
Copia profunda (Deep copy)#
Se puede realizar una copia profunda (deep copy) que funcione para listas anidadas. Pero, para ello, hay que recurrir a bibliotecas de funciones: la función que necesitamos, deepcopy(), está en el módulo copy.
from copy import deepcopy
a = [5, 2, [3, 4]]
b = deepcopy(a)
El diagrama resultante después de la copia profunda será el que se muestra a continuación.
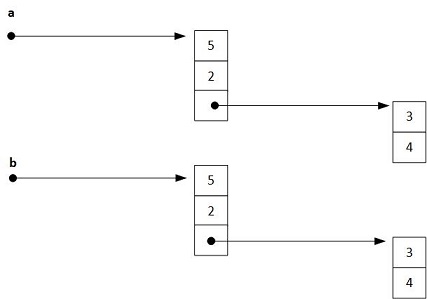
from copy import deepcopy
a = [5, 2, [3, 4]]
b = deepcopy(a)
a[0] = 10
a[2][0] = 20
print('a: ', a)
print('b: ', b)
a: [10, 2, [20, 4]]
b: [5, 2, [3, 4]]
Operadores de comparación con secuencias#
Estos operadores comparan de izquierda a derecha elemento a elemento en posiciones correlativas. Salvo == y !=, el resto no están definidos para rangos.
Operador |
Descripción |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
lista1 = [1, 2, 3, 4, 5]
lista2 = [1, 2, 3, 4, 5]
if lista1 == lista2:
print(f'{lista1} es igual a {lista2}')
tupla1 = (1, 2, 3, 4, 5)
tupla2 = (1, 1, 30, 30, 50)
if tupla1 > tupla2:
print(f'{tupla1} es mayor que {tupla2}')
rango1 = range(0, 10)
rango2 = range(1, 10)
rango1 < rango2
[1, 2, 3, 4, 5] es igual a [1, 2, 3, 4, 5]
(1, 2, 3, 4, 5) es mayor que (1, 1, 30, 30, 50)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[52], line 13
11 rango1 = range(0, 10)
12 rango2 = range(1, 10)
---> 13 rango1 < rango2
TypeError: '<' not supported between instances of 'range' and 'range'
Casos de uso de listas y tuplas#
Mutabilidad#
La principal diferencia entre listas y tuplas es la mutabilidad. Si la aplicación necesita de una secuencia de datos que puede sufrir modificaciones durante la ejecución del programa, entonces la secuencia a elegir es obviamente la lista.
Heterogeneidad de los elementos#
Tanto listas como tuplas pueden contener elementos de diferentes tipos de datos. Un elemento de una lista puede ser a su vez otra lista (listas anidadas) o una tupla, y viceversa.
En general, es un uso extendido pero no obligado:
Usar listas para almacenar datos homogéneos en secuencias que puedan cambiar de tamaño durante la ejecución del programa o que puedan alterar el valor de sus elementos. Sería el equivalente a los vectores de lenguajes como C++.
Usar tuplas para almacenar datos homogéneos o heterogéneos cuya estructura o valor no vaya a sufrir modificaciones. Sería el equivalente a las estructuras en C++.
En la siguiente celda se muestra un ejemplo en el que, siguiendo las pautas anteriores, se usan:
tuplas, para conformar una estructura fija de datos heterogéneos correspondiente a alumnos
una lista, para almacenar un vector homogéneo, probablemente cambiante, de alumnos
nombre_apellidos_1 = 'Juan', 'Sierra', 'Gómez'
dni_1 = '13120714E'
nia_1 = 123434
alumno_1 = nombre_apellidos_1, dni_1, nia_1
print(nombre_apellidos_1, 'es una tupla homogénea formada por 3 campos str')
print(alumno_1, 'es una tupla heterogénea formada por una tupla, un dato str y un dato int')
nombre_apellidos_2 = 'Pedro', 'López', 'Roldán'
dni_2 = '73131714F'
nia_2 = 471394
alumno_2 = nombre_apellidos_2, dni_2, nia_2
nombre_apellidos_3 = 'María de las Mercedes', 'Santurce', 'Bilbao'
dni_3 = '17571924T'
nia_3 = 729219
alumno_3 = nombre_apellidos_3, dni_3, nia_3
# Simulamos la formación dinámica de la lista
lista_alumnos = [] # Lista homogénea construida dinámicamente a partir de tuplas
lista_alumnos.append(alumno_1)
lista_alumnos.append(alumno_2)
lista_alumnos.append(alumno_3)
print(lista_alumnos)
('Juan', 'Sierra', 'Gómez') es una tupla homogénea formada por 3 campos str
(('Juan', 'Sierra', 'Gómez'), '13120714E', 123434) es una tupla heterogénea formada por una tupla, un dato str y un dato int
[(('Juan', 'Sierra', 'Gómez'), '13120714E', 123434), (('Pedro', 'López', 'Roldán'), '73131714F', 471394), (('María de las Mercedes', 'Santurce', 'Bilbao'), '17571924T', 729219)]
Cadenas de caracteres#
Las cadenas de caracteres son secuencias inmutables de caracteres alfanuméricos. La mayor parte de las veces se trabaja con las cadenas tomándolas en su conjunto. Pero es perfectamente posible acceder a los caracteres individuales, utilizando los conceptos vistos previamente.
cadena = "La cadena de caracteres es una secuencia"
print(f'''La frase "{cadena}" tiene una longitud de {len(cadena)} caracteres.
Comienza por \'{cadena[0]}\' y termina por \'{cadena[-1]}\'.''')
La frase "La cadena de caracteres es una secuencia" tiene una longitud de 40 caracteres.
Comienza por 'L' y termina por 'a'.
Si intentamos modificar un elemento, se origina una excepción.
cadena = "hola"
cadena[0] = 'H'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[55], line 2
1 cadena = "hola"
----> 2 cadena[0] = 'H'
TypeError: 'str' object does not support item assignment
En los siguientes temas iremos introduciendo métodos específicos de las cadenas de caracteres. Como adelanto, veamos como el operador in aplicado a una cadena de caracteres es capaz de determinar si una subcadena está contenida dentro de otra.
cadena = 'La vida es dura.'
subcadena = 'dura'
if subcadena in cadena:
print(f'La subcadena \'{subcadena}\' está contenida en la cadena \'{cadena}\'')
La subcadena 'dura' está contenida en la cadena 'La vida es dura.'
Otro operador habitual, utilizado para concatenar cadenas de caracteres, es +=. Recordemos que, dada la inmutabilidad, la identidad de la cadena puede variar.
cadena = 'Hola'
identidad = id(cadena)
cadena += ' mundo.'
print(f'''Tras la concatenación, la nueva cadena \'{cadena}\' tiene una identidad { id(cadena)},
que es diferente de la original, {identidad}''')
Tras la concatenación, la nueva cadena 'Hola mundo.' tiene una identidad 2481772880816,
que es diferente de la original, 2481789603568